
[2021-01-26] GraphACT: Accelerating GCN Training on CPU-FPGA Heterogeneous Platforms
Published:
This paper is a CPU-FPGA heterogenrous platform for GCN training. CPU will do the communication intensive operations, and leave the computation intensive parts to CPU.
Background and Motivation
It is challenging to accelerate Graph Convolutional Networks because: (1) substantial and irregular data communication to propagate information within the graph (2) intensive computation to propagate information along the neural network layers (3) Degree-imbalance ofgraph nodes can significantly degrade the performance of feature propagation.
GCN acceleration compared with existing graph analytic problems (1) traditional graph analytics often propagate scalars along the graph edges, while GCNs propagate long feature vectors (2) traditional graph analytics often propagate information within the full graph, while GCNs propagate within minibatches.
Optimizations
Training Algorithm Selection:
- minibatch by sampling training graph. The algorithm will samples subgraph instead of GCN layers
Redundancy Reduction:
- perform pre-processing to compute the partial sum
- common pairs of neighbors, size of 2 (Could it be larger, or dynamic according the graph topolopy?)
Architecture Design
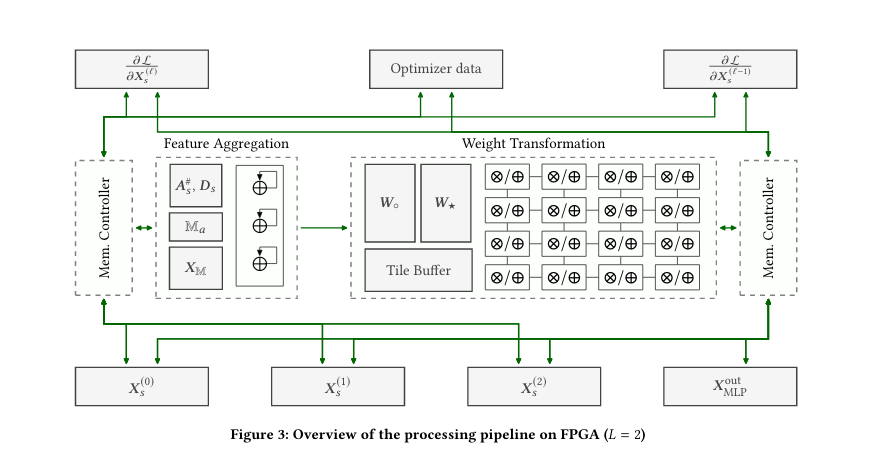 CPU: communication intensive part, including graph sampling
CPU: communication intensive part, including graph sampling
FPGA: computation intensive part, including forward and backward pass
How to improve training throughput:
- reduce the overhead in external memory access: set the minibatch size so that the subgraph could fit in BRAM capacity
- increase the utilization of the on-chip resources
- feature aggrefation module: 1D accumulator array - parallelizing on the feature dimension
- weight transformation module: 2D systolic array to compute the dense matrix product
Evaluation
Compared with CPU baseline, 12x to 15x speedup; Compared with GPU baseline, 1.1x to 1.5x faster convergence rate. The authors said that their work has higher accuracy comapred with one previous work. But I wonder if all the work use the same subgraph sampling algorithm, would the accuracy be different.
Insights
Although I feel like this work focus more on the engineering part rather than the novel architecture design. The challenge it proposes is insightful for me: memory access and load-balance. I wonder if this design is scalable. It seems that the BRAM size is the bottleneck, could we do more optimization on the memory access?