
[2021-10-12] ISCA 2021 Section 3A: Machine Learning 1
Published:
This reading blog is about three papers in Section 3A: Machine Learning 1 of ISCA 2021.
RaPiD: AI Accelerator for Ultra-Low Precision Training and Inference
This accelerator supports mixed precisions for both training and inference: 16 and 8-bit floating-point and 4 and 2-bit fixed point. It imporves both performance(TOPS) and energy efficiency(TOPS/W) at ultra-low preceision. In my opinion, this work contributes more on the engineering part (architecture).
MPE Array: Mixed-Precision PE Array
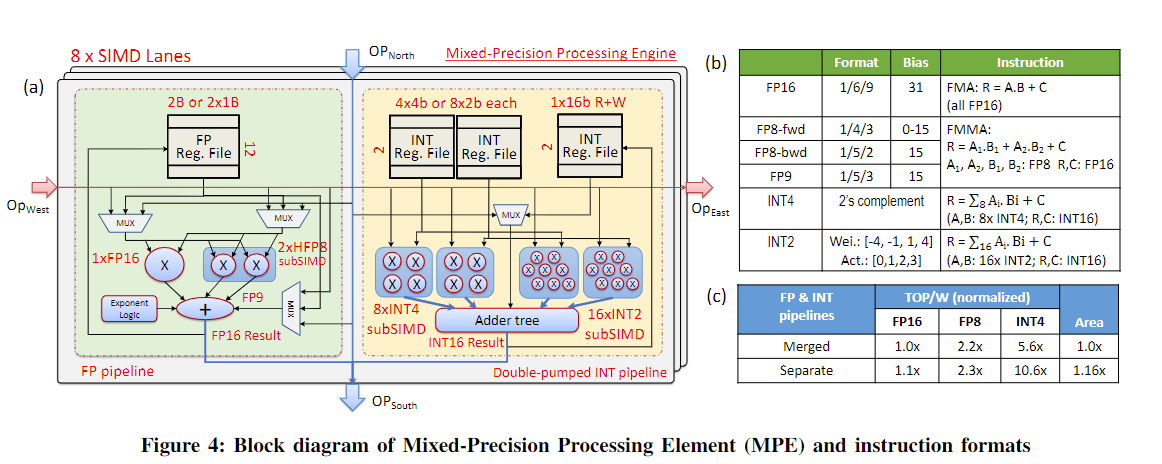 Here are the challenges and solutions for scaled precisions. 1) Challenge: Support both INT and FP pipelines. Solution: Seperation of the integer and floating point pipelines. 2) Challenge: FP8 for training has two format, one for forward(1,5,3), another for backward(1,4,3). Solution: On-the-fly conversion. Both ceonver to 9bit (1,5,3) 3) Challenge: performance scaling from FP16 to FP8. Solution: sub-SIMD partition. 4) Challenge: IN4/INT2 inference circuit-level optimizations. Solution: double INT4/INT2 engines; Operand Reuse: Sub-SIMD
Here are the challenges and solutions for scaled precisions. 1) Challenge: Support both INT and FP pipelines. Solution: Seperation of the integer and floating point pipelines. 2) Challenge: FP8 for training has two format, one for forward(1,5,3), another for backward(1,4,3). Solution: On-the-fly conversion. Both ceonver to 9bit (1,5,3) 3) Challenge: performance scaling from FP16 to FP8. Solution: sub-SIMD partition. 4) Challenge: IN4/INT2 inference circuit-level optimizations. Solution: double INT4/INT2 engines; Operand Reuse: Sub-SIMD
Sparsity-aware Zero-gating and Frequency Throttling
1) Zero-gating for zero operands 2) Sparsity-aware frequency throttling. Use clock throttling rather than DVFS. (Although I don’t know what clock throttling); not in critical path
Data Communication Among Cores and Memory
Bi-directional ring interconnnection to communicate data between cores and memory. Data fetch latency can be hidden by double-buffering data in L1 overlapped with computations; Assign unique identification tags; Support multi-cast comminucations; Support for “request aggregation”