
[2021-02-20] Analyzing and Mitigating Data Stalls in DNN Training
Published:
Most DNN acclerator papers I read focus on DNN inference rather than training. From this paper, I learned that the bottleneck for DNN training is I/O for fetching data and CPU side for preprocessing.
Background
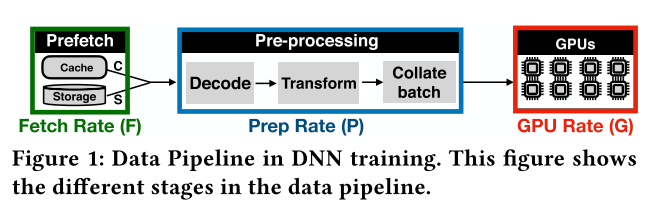
The figure above shows the data pipeline in DNN training. (1) A minibatch of data items is fetched from storage. (2) The data items are pre-processed, for e.g.,, for image classifica- tion, data items are decompressed, and then randomly cropped, resized, and flipped. (3) The minibatch is then processed at the GPU to obtain the model’s prediction (4) A loss function is used to determine how much the prediction deviates from the right answer (5) Model weights are updated using computed gradients
Analyzing data stalls
Technique
Existing profiling data stalls frameworks like Pytorch and Tensorflow are inaccurate and insufficient: 1) They cannot accurately provide the split up of time spent in data fetch (from disk or cache) and pre-processing operations 2) Frameworks like PyTorch and libraries like DALI use several concurrent processes (or threads) to fetch and pre-process data; But GPU processes wait to synchronize weight upates at batch boundaries, so a data stall may affect the GPU compute time for other GPUs
This paper develop a tool, DS-Analyzer to overcome these limitations by using a dofferential approach: 1) Measure ingestion rate with no fetch or prep stalls 2) Measure prep stalls with a subset of given dataset which is entirely cached in memory. 3) Measure fetch stalls by clearing all caches and compare the difference between 2)
Results
- Pay a one-time download cost for the dataset, and reap benefits of local-SSD accesses thereafter. Because the cost of downloading the entire dataset in the first epoch is amortized.
When datasets cannot be fully cached:
- Fetch stalls are common if the dataset is not fully cached in memory, which is obvious.
- OS Page Cache is inefficient for DNN training because it leads to trashing.
- Lack of coordination among caches leads to redundant I/O in distributed training.
When datasets could fit in memory:
- DNNs need 3–24 CPU cores per GPU for pre-processing.
- DALI is able to reduce, but not eliminate prep stalls.
- As compute gets faster (either due to large batch sizes, or the GPU getting faster), data stalls squander the benefits due to fast compute.
- Redundant pre-processing for concurrent jobs in HP search results in high prep stalls
Mitigate data stalls
- MinIO cache (single-server training)
- DNN data access pattern: repetitive across epochs and random within an epoch.
- items, once cached, are never replaced in the DNN cache
- Patitioned MinIO cache (distributed-server training)
- Data transfer over commodity TCP stack is much faster than fetch- ing a data item from its local storage, on a cache miss.
- Whenever a local cache miss happens in the subsequent epoch at any server, the item is first looked up in the metadata; if present, it is fetched from the respective server over TCP, else from its local storage.
- Coordinated Prep (single-server training)
- each job processes the entire dataset exactly once per epoch