
[2021-01-07] Echo: Compiler-based GPU Memory Footprint Reduction for LSTM RNN Training
Published:
This is a paper about GPU memory footprint reduction using selective recomputation during LSTM training process. Although I do not know much about LSTM network, this paper is quite clear and easy to understand.
Backgound and Observation
LSTM will have intermediate results 9x larger than the output size. And by the nature of backpropagation, some featuremaps have to be stashed in memory during the forward pass to compute the gradients. Two observation during the LSTM training on GPU: (i) the feature maps of the attention and RNN layers consume most of the GPU memory (feature maps are the data entries saved in the forward pass to compute the gradients during the backward pass), (ii) the runtime is unevenly distributed across different layers (fully-connected layers dominate the runtime while other layers are relatively lightweight). And there is an observation of the training throughput comparing ResNet-50(CNN model) with NMT(LSTM model).The training throughput saturates as the batch size increases for ResNet-50, which means the GPU compute units have been almost fully utilized. But for NMT, the training throughput increases linearly with the batch size, but such increase stops when the model hits the GPU memory capacity wall. From the comparison, the authors draw the conclusion that, in LSTM RNN-based model, performance is limited by the GPU memory capacity
Ideas
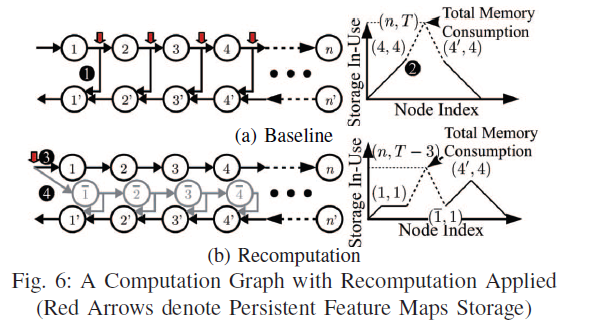 The dependencies shown in (a) means that th featuremap has to be stashed, resulting in the bottleneck of GPU. So (b) tries to remove the dependecies by recomputation. Such recomputation idea has been proposed already, but did not have good performance because the previous work failed to estimate footprint reduction and runtime overhead accurately. For footprint reduction, a practical recomputation strategy should involve the comparison between the feature maps that are released and those that are newly allocated. Besides, the global impact of those allocations should be considered. But evaluating all possible recomputation has large runtime complexity. So the author proposes to partition the whole computation graph into small subgraphs. Compute-heavy layers form the natural boundaries since they are never recomputed. For runtime overhead estimation. The authors look into the layer properties and be less conservative of the recompution overhead. For example, fully-connected layer gradients has not depedency of the output, which means no recompution needed. ReLU activations and dropout layers can be stored in 1-bit binary format.
The dependencies shown in (a) means that th featuremap has to be stashed, resulting in the bottleneck of GPU. So (b) tries to remove the dependecies by recomputation. Such recomputation idea has been proposed already, but did not have good performance because the previous work failed to estimate footprint reduction and runtime overhead accurately. For footprint reduction, a practical recomputation strategy should involve the comparison between the feature maps that are released and those that are newly allocated. Besides, the global impact of those allocations should be considered. But evaluating all possible recomputation has large runtime complexity. So the author proposes to partition the whole computation graph into small subgraphs. Compute-heavy layers form the natural boundaries since they are never recomputed. For runtime overhead estimation. The authors look into the layer properties and be less conservative of the recompution overhead. For example, fully-connected layer gradients has not depedency of the output, which means no recompution needed. ReLU activations and dropout layers can be stored in 1-bit binary format.
Implementation & Evaluation
The paper integrate Echo in NNVM, which is the computation graph compiler for MXNet. And the work is able to use a compiler-based optimization pass to automatically insert the recomputation in the program. Echo reduces the GPU memory footprint by 1.89× on average and 3.13× maximum with marginal runtime overhead.