
[2020-07-20]Optimus Prime: Accelerating Data Transformation in Servers
Published:
This paper proposes an accelerator for Data Transformation (DT) in servers in ASPLOS 2020.
Background and Motivation
Microservices has emerged for its scalability, reliability and development velocity. Because code is often written in different languages with their own data format, Data Transformation (DT) is needed to performed for desired format. The work observed that up to 30% of service time being spent in DT.
The process of DT is as follows: Serialize fileds in application 1; send to application2; Application2 deserialize the messages for its own usage To serialize an application, each field is individually transformed using the serializeField function based on its type. The output of each field contains a key (aka. tag), acting as an identifier for the field, and the serialized bytes of data.
DT is an inherently field-parallel task, but its SW implementation is not. It relies on implicit ILP; On the other hand, the fields are fine-grained, which cannot amortize the synchronization cost of thread-level parallelism.
Architecture
The paper propose a data transformation accelerator(DAT) with explicit field-level parallel DT abstraction, called Optimus Prime(OP). Each {type, address} pair represents a field. The DT abstraction is referred as schema, which resides in memory.
DT tasks need a fast interface with aacelerator with the accelerator, which need a on-chip integration for quick access for data, and use polling an memory-mapped I-O(MMIO) to reduce invocation latency.
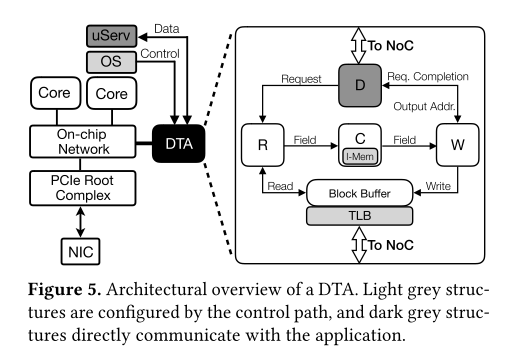 The overiew of DTA is shown in the figure above. Dispatch (D) comminicates with cores. Reader(R) parse the schema. Convertor(C) performs data transformation. The Converter is implemented as a simple pipeline with four stages. Writer(W) writes data to output bufer. Block Buffer acts as a scratchpad for the Reader and Writer. Prefetching and time sharing can hide memory latency.
The overiew of DTA is shown in the figure above. Dispatch (D) comminicates with cores. Reader(R) parse the schema. Convertor(C) performs data transformation. The Converter is implemented as a simple pipeline with four stages. Writer(W) writes data to output bufer. Block Buffer acts as a scratchpad for the Reader and Writer. Prefetching and time sharing can hide memory latency.
There are two choices for DTA location: a private DTA co-located with each core, or a shared DTA that is placed on one of the chip’s tiles. The two choices exhibts the tradeoff between latency variability and silicon provisioning. The authors chose the second one, because the silicon costs of private DTAs adds up quickly with increasing core counts.
The design details can be found in the paper.
Evaluation
$OP(n,m)$, n denotes the number of parallel pipelines, and m denotes the time-sharing degree - how many pipelines are time-shared. A single-pipeline OP (OP{1,1}) is 5x faster than baseline CPU without prefetching and time-sharing, and has another 2-4x improvement with prefetching and time-sharing.
The throughput of parallel-pipeline OP increases as it scales up. But the throughput plateaus beyond a certain number of pipelines because they, in aggregate, exhaust the available NoC bandwidth.
The area and power of OP is relatively small, with ~7% of a single core area for OP{3,4}.